
I am currently a research scientist at Shanghai AI Laboratory. My research interests include Embodied AI, Robotic Manipulation and Vision-Language-Action (VLA) model.
I received my PhD degree from Robotics Institute, Shanghai Jiao Tong University, supervised by Prof. Honghai Liu, and obtained my bachelor’s degree from Central South University. I am currently working with Jiangmiao Pang on Embodied AI. Over the preceding period, I have worked with Prof. Hongyang Li and Prof. Yu Qiao.
📝 Selected Publications
🤖 Embodied AI * indicates equal contribution, ✉️ indicates corresponding author

InternVLA-A1: Unifying Understanding, Generation, and Action for Robotic Manipulation
InternVLA-A1 Team (Jia Zeng: project lead & core contributor)
-
We present InternVLA-A1, which unifies scene understanding, visual foresight generation, and action execution into a single framework.
- 🔮 The Core: Synergizes MLLM’s semantic understanding with world-model-style dynamic prediction, to “imagine” the future and guide adaptive actions.
- 🚀 The Fuel: Enables joint training on heterogeneous data sources over real-world robot data, synthetic simulation data, and egocentric human videos.
- ⚡ The Output: A VLA model that tackles highly dynamic scenarios with effortless mastery.
- arXiv | Code | Model | Project Page

InternData-A1: Pioneering High-Fidelity Synthetic Data for Pre-training Generalist Policy
Yang Tian$^\ast$, Yuyin Yang$^\ast$, Yiman Xie$^\ast$, Zetao Cai$^\ast$, Xu Shi$^\ast$, Ning Gao, Hangxu Liu, Xuekun Jiang, Zherui Qiu, Feng Yuan, Yaping Li, Ping Wang, Junhao Cai,
Jia Zeng✉️, Hao Dong✉️, Jiangmiao Pang✉️
-
We propose a high-fidelity synthetic data InternData-A1, which contains over 630k trajectories and 7,433 hours .
- This work provides the first evidence that synthetic data alone can match the performance of the strongest 𝜋-dataset in pre-training a VLA model, revealing the substantial value of large-scale simulation.
- arXiv | Dataset | Project Page
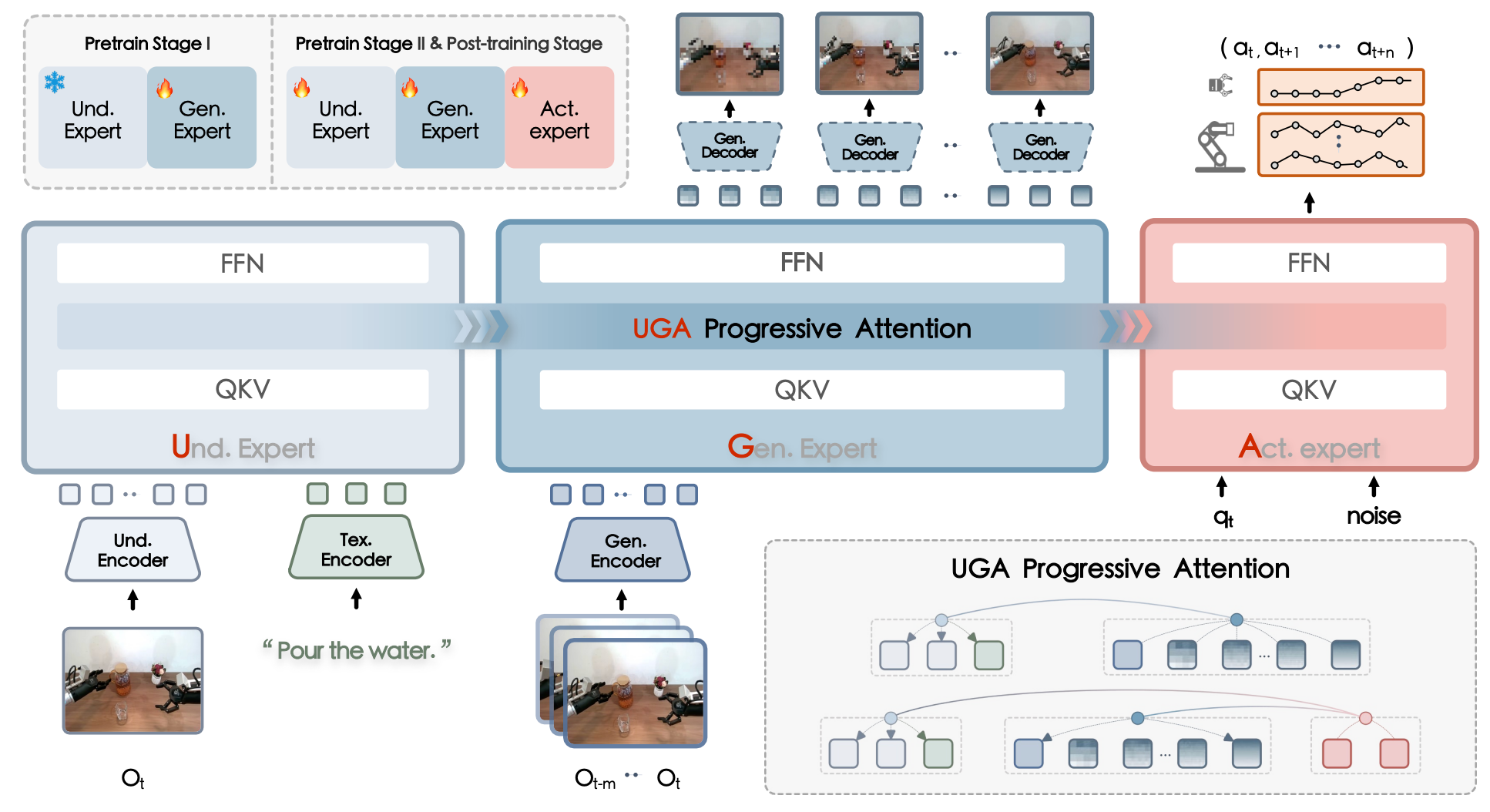
F1: A vision-language-action model bridging understanding and generation to actions
Qi Lv$^\ast$, Weijie Kong$^\ast$, Hao Li$^\ast$, Jia Zeng✉️, Zherui Qiu, et al.
-
We introduce F1, a novel paradigm by integrating visual foresight generation into the decision-making pipeline. Our model employs a Mixture-of-Transformer architecture with dedicated modules for perception, foresight generation, and control, thereby bridging understanding, generation, and actions through predictive inverse dynamics modeling.
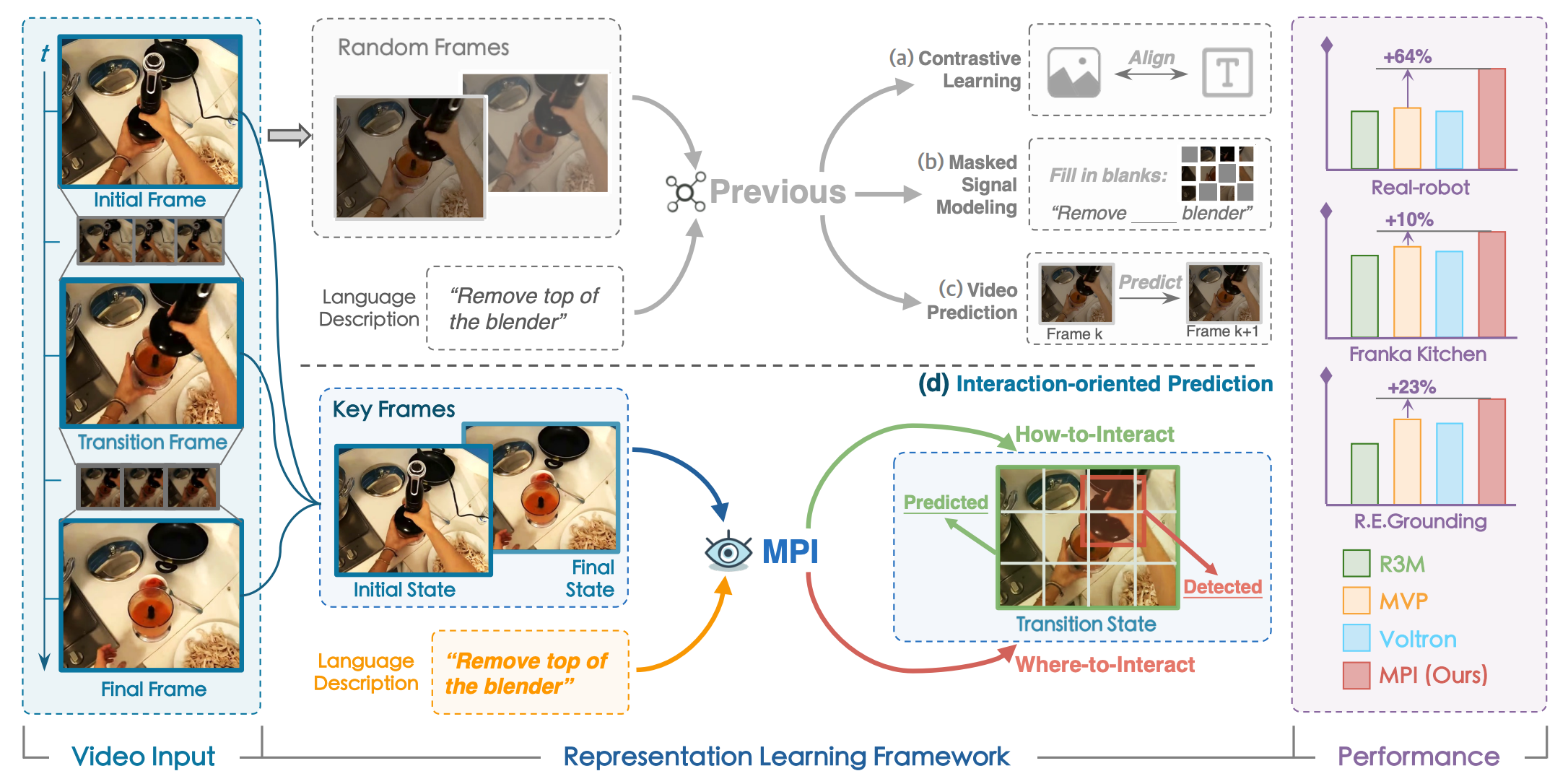
Learning Manipulation by Predicting Interaction
Jia Zeng$^\ast$, Qingwen Bu$^\ast$, Bangjun Wang$^\ast$, Wenke Xia$^\ast$, Li Chen, Hao Dong, H.Song, D.Wang, D.Hu, P.Luo, H.Cui, B.Zhao, X.Li, Y.Qiao, Hongyang Li
- We propose a representation learning framework towards robotic manipulation that learns Manipulation by Predicting Interaction (MPI).
- RSS 2024 | Project Page | Code
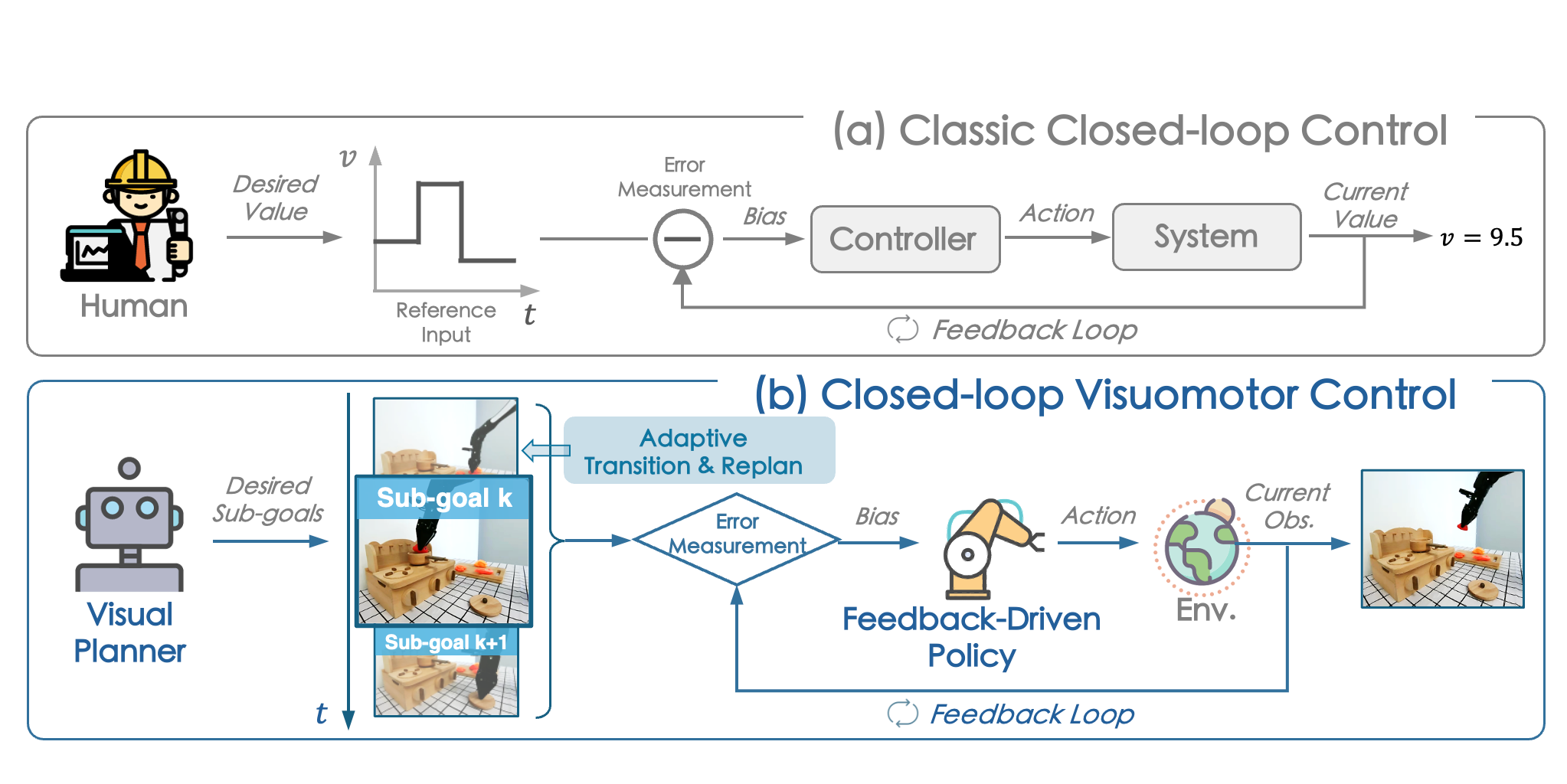
Closed-Loop Visuomotor Control with Generative Expectation for Robotic Manipulation
Qingwen Bu$^\ast$, Jia Zeng$^\ast$, Chen Li$^\ast$, Yanchao Yang, Guyue Zhou, Junchi Yan, Ping Luo, Heming Cui, D.Hu, Yi Ma, Hongyang Li
- We propose CLOVER, which employs a text-conditioned video diffusion model for generating visual plans as reference inputs, then leverages these sub-goals to guide the feedback-driven policy to generate actions with an error measurement strategy.
- NeurIPS 2024 | Code
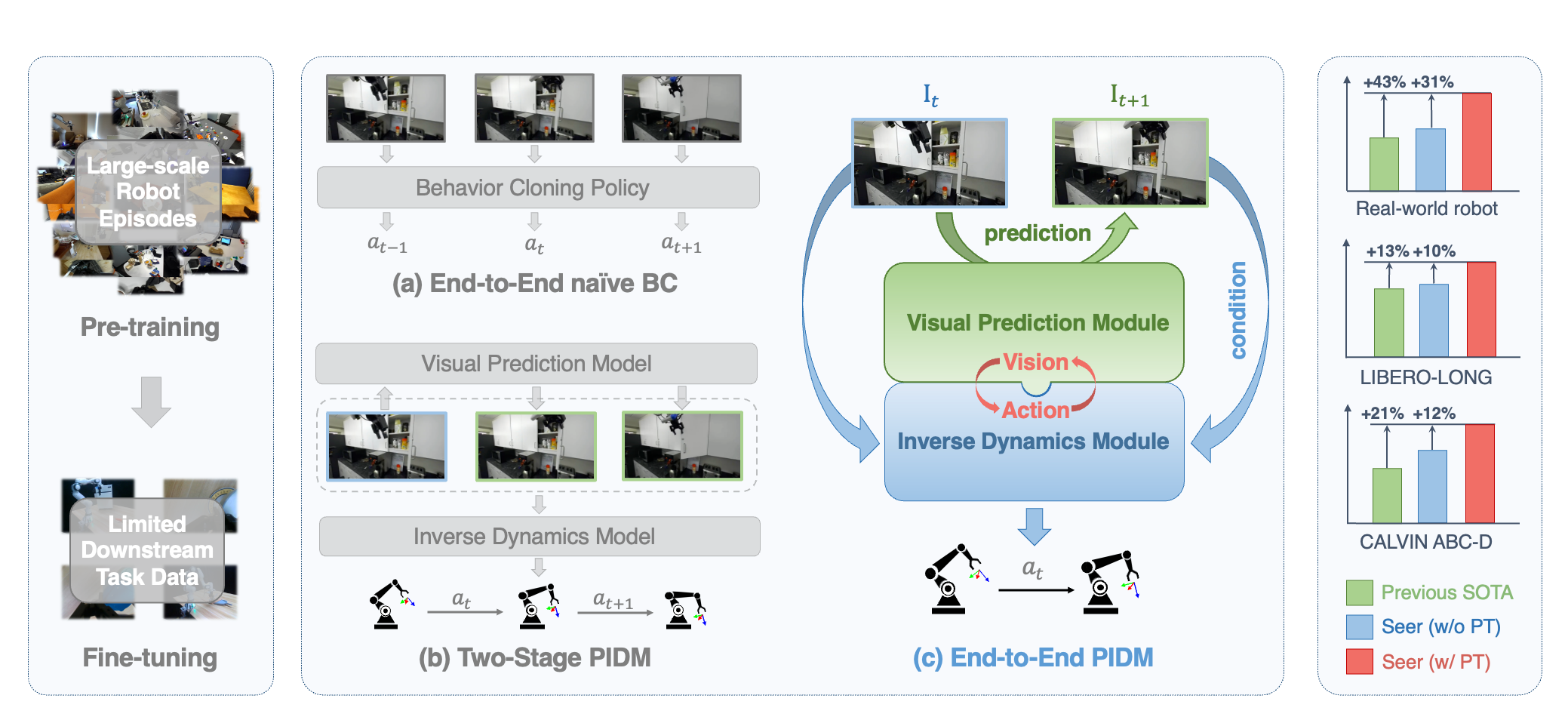
Predictive Inverse Dynamics Models are Scalable Learners for Robotic Manipulation
Yang Tian$^\ast$, Sizhe Yang$^\ast$, Jia Zeng, Ping Wang, Dahua Lin, Hao Dong, Jiangmiao Pang
-
We propose an end-to-end model, Seer, which employs an inverse dynamics model based on the robot’s predicted visual states to forecast actions. We term such architectural framework the Predictive Inverse Dynamics Model (PIDM).
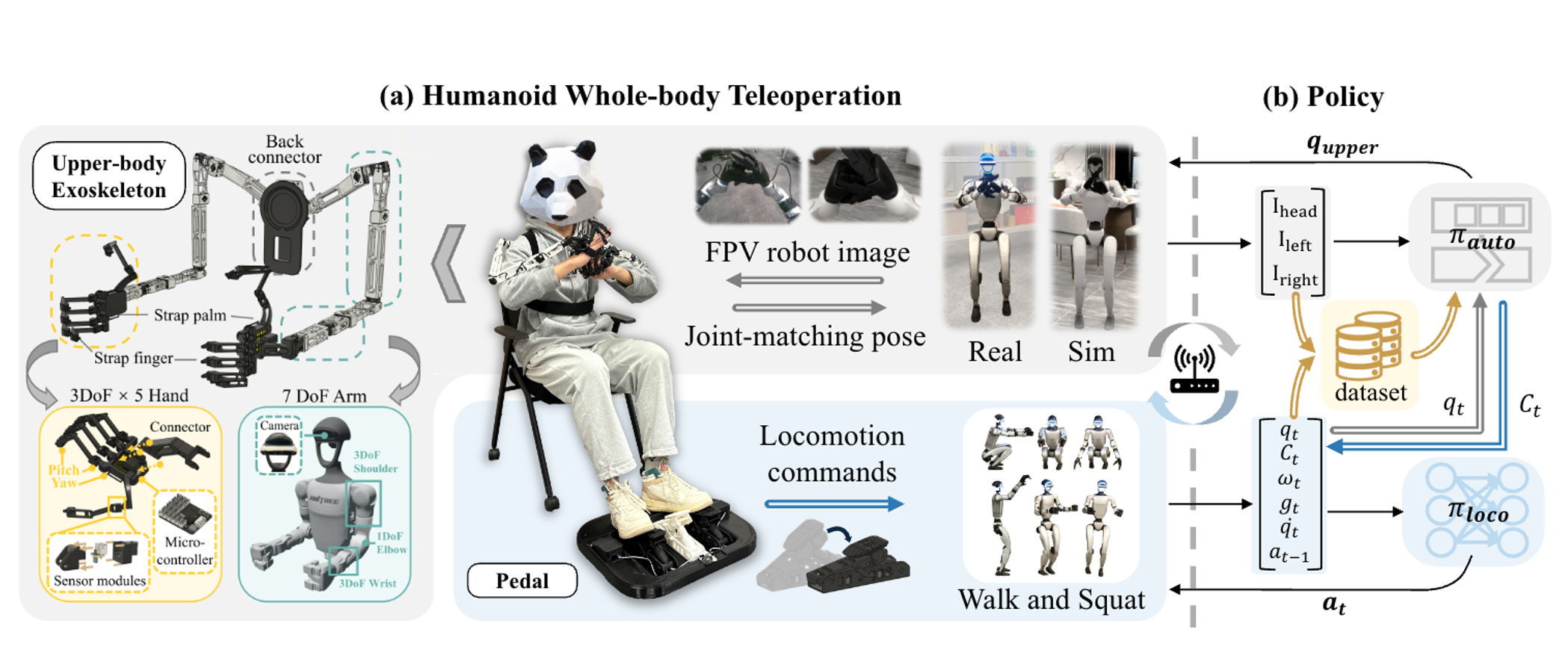
HOMIE: Humanoid Loco-Manipulation with Isomorphic Exoskeleton Cockpit
Qingwei Ben$^\ast$, Feiyu Jia$^\ast$, Jia Zeng, Junting Dong, Dahua Lin, Jiangmiao Pang
-
we propose HOMIE, a novel humanoid teleoperation cockpit integrates a humanoid loco-manipulation policy and a low-cost exoskeleton-based hardware system.
-
RSS 2025 | Project Page | Code
🚗 Autonomous Driving
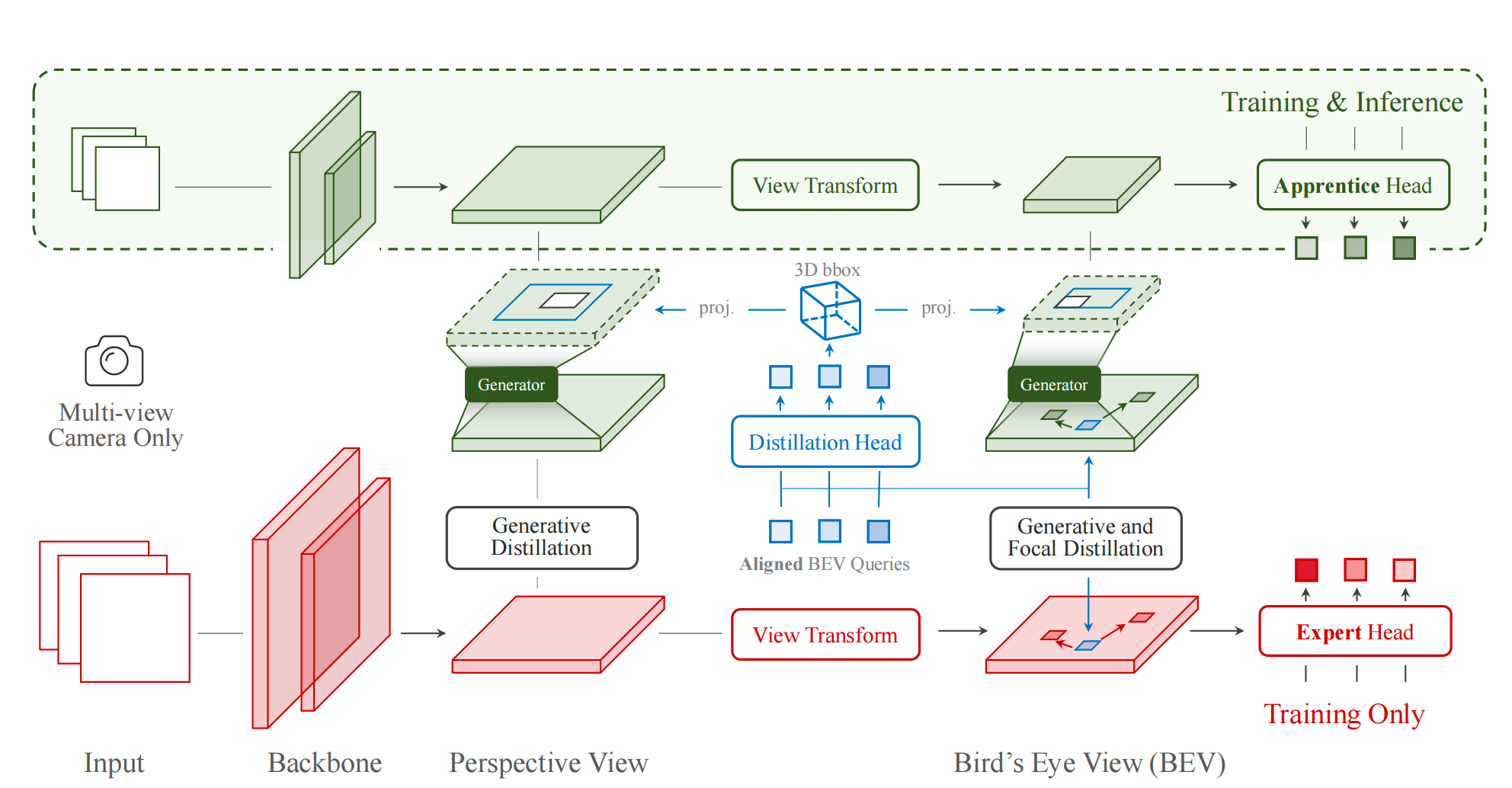
Distilling Focal Knowledge From Imperfect Expert for 3D Object Detection
Jia Zeng, Li Chen, Hanming Deng, Lewei Lu, Junchi Yan, Yu Qiao, Hongyang Li
- We apply knowledge distillation to camera-only 3D object detection, investigate how to distill focal knowledge when confronted with an imperfect 3D object detector teacher.
- CVPR 2023
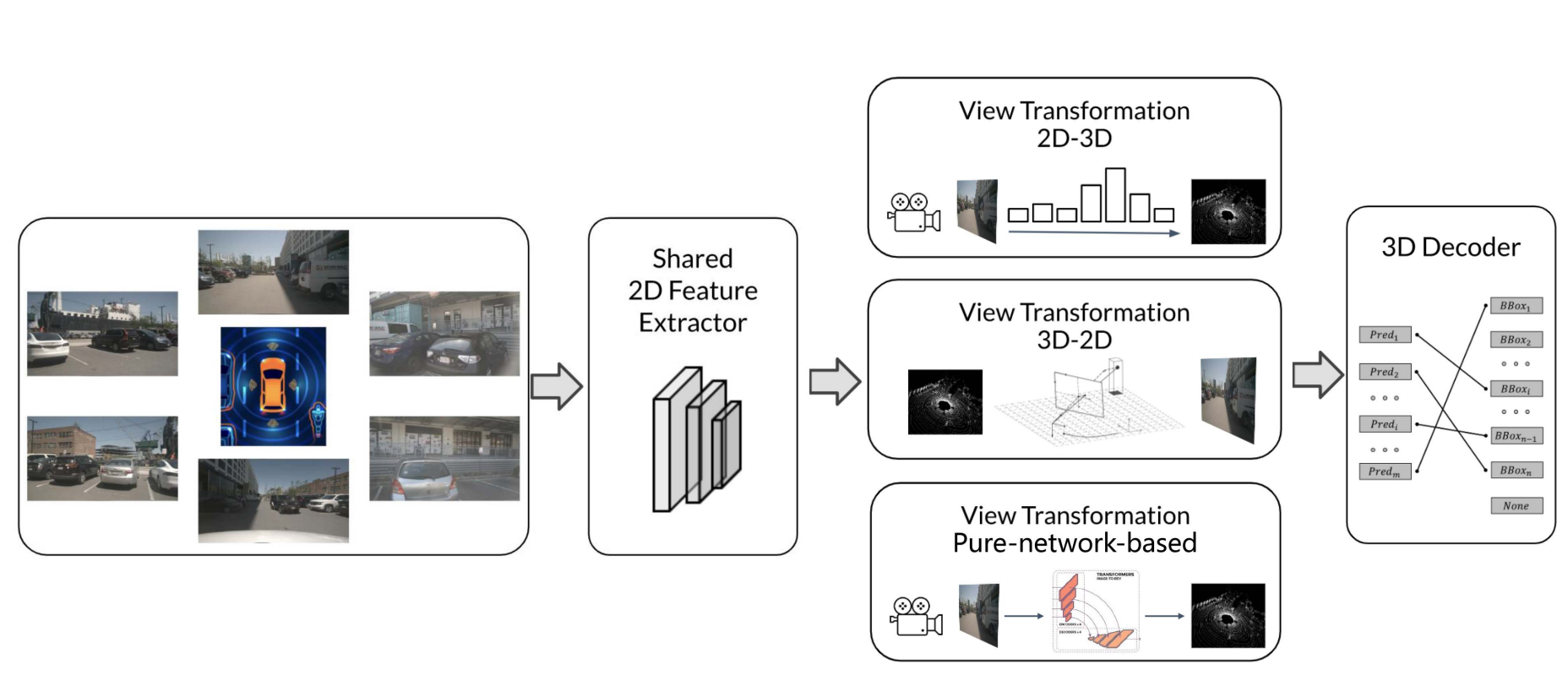
Delving Into the Devils of Bird’s-Eye-View Perception: A Review, Evaluation and Recipe
Jia Zeng: Co-first author
- we conduct a thorough review on Bird’s-Eye-View (BEV) perception in recent years and provide a practical recipe according to our analysis in BEV design pipeline.
- IEEE T-PAMI | Github
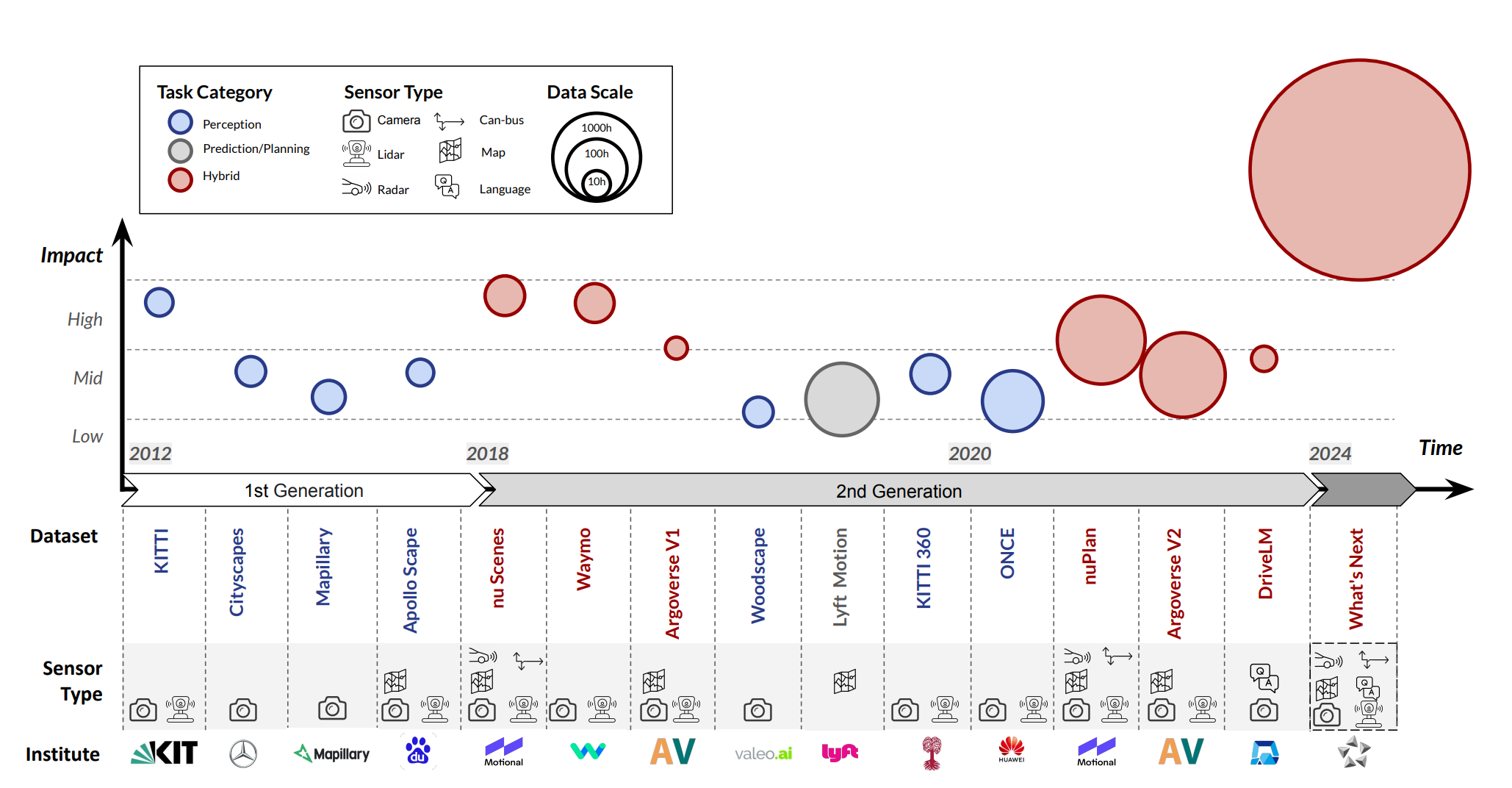
Open-sourced data ecosystem in autonomous driving: the present and future
Jia Zeng: Co-first author
- We undertakes an exhaustive analysis and discourse regarding the characteristics and data scales that future third-generation autonomous driving datasets should possess.
- SCIENTIA SINICA Informationis | arXiv
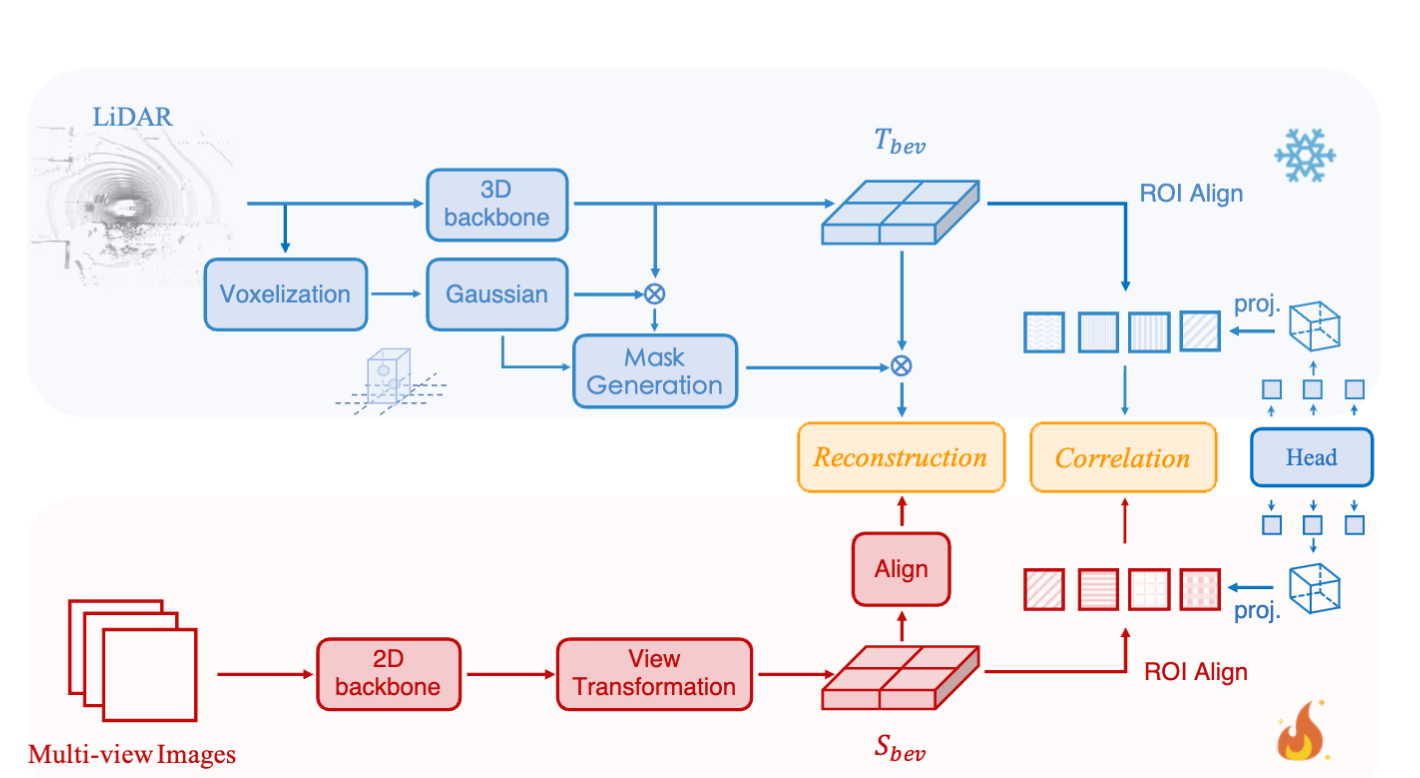
Geometric-aware Pretraining for Vision-centric 3D Object Detection
Linyan Huang, Huijie Wang, Jia Zeng, et al.
- We propose a geometric-aware pretraining method called GAPretrain, which distills geometric-rich information from LiDAR modality into camera-based 3D object detectors.
- arXiv
🧑💻 Career Experience

Shanghai AI Labotory, Research scientist
2023.09 - (present).
- Embodied foundation model and generalizable robotic manipulation.
Shanghai AI Labotory, Research intern
2022.04 - 2023.06, Supervisor: Prof. Hongyang Li.
- Birds-Eye-View perception and Knowledge distillation for 3D object detection.
🎓 Education
Robotics Institute, Shanghai Jiao Tong University
2017.09 - 2023.8, Supervisor: Prof. Honghai Liu.
- Bio-signal based human motion recognition and human-machine interaction.
Central South University
2013.09 - 2017.06.
- Mechatronics engineering
- Image processing
💼 Service
- Reviewer for
CVPR,ECCV,NeurIPS,ICLR,ICML, etc. - Member of CAAI-Embodied AI Committee.